2025
Nipping Rumors in the Bud: Retrieval-Guided Topic Adaptation for Test-Time Detection of Fake News Videos
Jian Lang, Rongpei Hong, Ting Zhong, Yong Wang, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2026 CCF-A Robustness Multimodal Learning Video Analysis & Detection
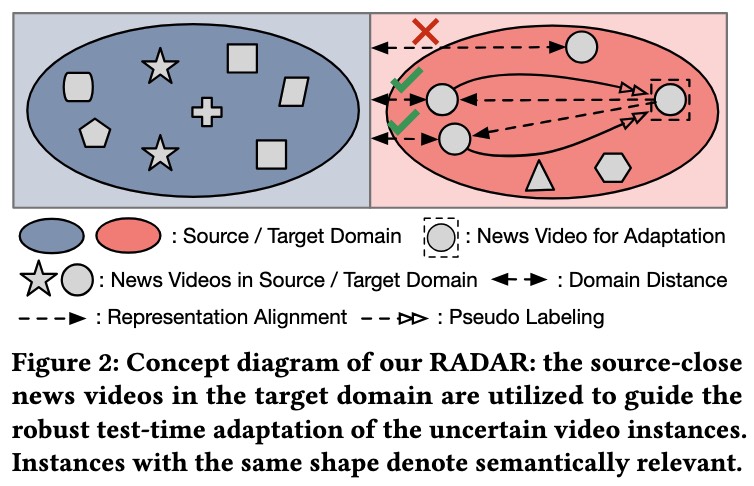
We propose RADAR, a novel retrieval-augmented distribution alignment and target-aware self-training framework that, for the first time, enables robust test-time adaptation for fake news video detection under drastic topic-level distribution shifts.
Nipping Rumors in the Bud: Retrieval-Guided Topic Adaptation for Test-Time Detection of Fake News Videos
Jian Lang, Rongpei Hong, Ting Zhong, Yong Wang, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2026 CCF-A Robustness Multimodal Learning Video Analysis & Detection
We propose RADAR, a novel retrieval-augmented distribution alignment and target-aware self-training framework that, for the first time, enables robust test-time adaptation for fake news video detection under drastic topic-level distribution shifts.
From Shallow Humor to Metaphor: Towards Label-Free Harmful Meme Detection via LMM Agent Self-Improvement
Jian Lang, Rongpei Hong, Ting Zhong, Leiting Chen, Qiang Gao, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2026 CCF-A Robustness Multimodal Learning Large Multimodal Model
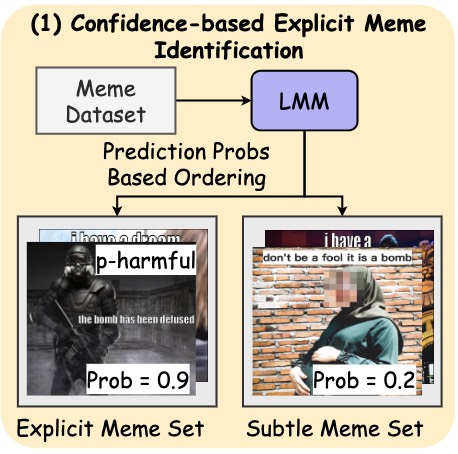
We propose ALARM, a label-free harmful meme detection framework powered by Large Multimodal Model self-improvement, which mitigates label scarcity and enables prompt and robust adaptation to evolving harmful content in web memes.
From Shallow Humor to Metaphor: Towards Label-Free Harmful Meme Detection via LMM Agent Self-Improvement
Jian Lang, Rongpei Hong, Ting Zhong, Leiting Chen, Qiang Gao, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2026 CCF-A Robustness Multimodal Learning Large Multimodal Model
We propose ALARM, a label-free harmful meme detection framework powered by Large Multimodal Model self-improvement, which mitigates label scarcity and enables prompt and robust adaptation to evolving harmful content in web memes.
TAMEing Long Contexts in Personalization: Towards Training-Free and State-Aware MLLM Personalized Assistant
Rongpei Hong, Jian Lang, Ting Zhong†, Yong Wang, Fan Zhou († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2026 CCF-A Large Multimodal Model
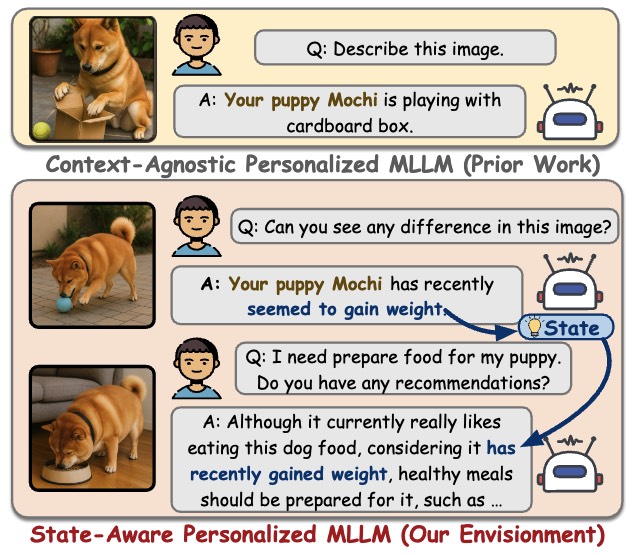
We propose TAME, a novel training-free and state-aware personalized Multimodal Large Multimodal Model (MLLM) assistant powered by double memories.
TAMEing Long Contexts in Personalization: Towards Training-Free and State-Aware MLLM Personalized Assistant
Rongpei Hong, Jian Lang, Ting Zhong†, Yong Wang, Fan Zhou († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2026 CCF-A Large Multimodal Model
We propose TAME, a novel training-free and state-aware personalized Multimodal Large Multimodal Model (MLLM) assistant powered by double memories.
Shedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jiao Li, Jian Lang, Xikai Tang†, Ting Zhong, Fan Zhou († corresponding author)
The Association for the Advancement of Artificial Intelligence (AAAI) 2026 CCF-A Robustness Multimodal Learning Video Analysis & Detection
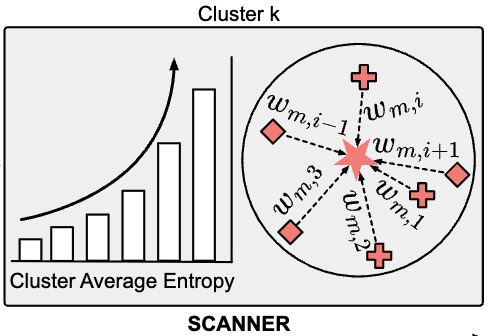
We propose SCANNER, the first test-time adaptation framework tailored for distribution shifting hate video detection.
Shedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jiao Li, Jian Lang, Xikai Tang†, Ting Zhong, Fan Zhou († corresponding author)
The Association for the Advancement of Artificial Intelligence (AAAI) 2026 CCF-A Robustness Multimodal Learning Video Analysis & Detection
We propose SCANNER, the first test-time adaptation framework tailored for distribution shifting hate video detection.
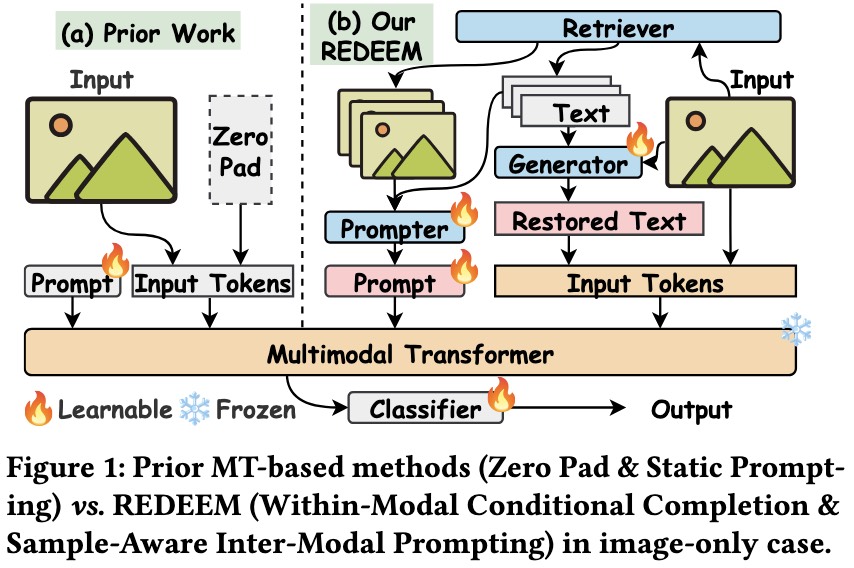
REDEEMing Modality Information Loss: Retrieval-Guided Conditional Generation for Severely Modality Missing Learning
Jian Lang, Rongpei Hong, Zhangtao Cheng, Yong Wang, Ting Zhong, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2025 CCF-A Robustness Multimodal Learning
We propose REDEEM, the extension work of our RAGPT accetped to AAAI 2025, a novel framework that pioneers a retrieval-guided conditional generation paradigm for enhancing the robustness of pre-trained Multimodal Transformer.
REDEEMing Modality Information Loss: Retrieval-Guided Conditional Generation for Severely Modality Missing Learning
Jian Lang, Rongpei Hong, Zhangtao Cheng, Yong Wang, Ting Zhong, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2025 CCF-A Robustness Multimodal Learning
We propose REDEEM, the extension work of our RAGPT accetped to AAAI 2025, a novel framework that pioneers a retrieval-guided conditional generation paradigm for enhancing the robustness of pre-trained Multimodal Transformer.
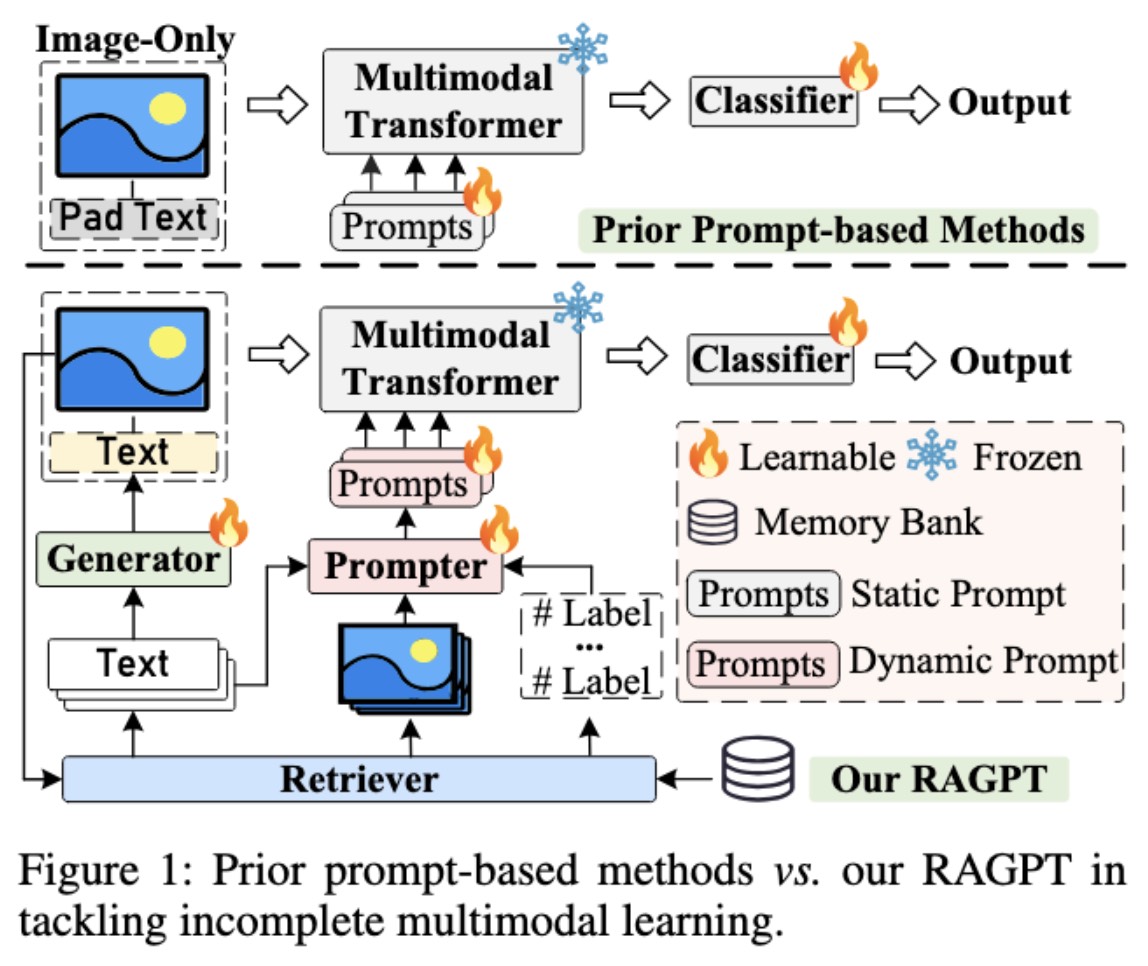
Retrieval-Augmented Dynamic Prompt Tuning for Incomplete Multimodal Learning
Jian Lang*, Zhangtao Cheng*, Ting Zhong, Fan Zhou† (* equal contribution, † corresponding author)
The Association for the Advancement of Artificial Intelligence (AAAI) 2025 CCF-A Robustness Multimodal Learning
We propose RAGPT, a novel retrieval-augmented dynamic prompt-tuning framework for enhancing the robustness of pre-trained Multimodal Transformer under modality missing conditions.
Retrieval-Augmented Dynamic Prompt Tuning for Incomplete Multimodal Learning
Jian Lang*, Zhangtao Cheng*, Ting Zhong, Fan Zhou† (* equal contribution, † corresponding author)
The Association for the Advancement of Artificial Intelligence (AAAI) 2025 CCF-A Robustness Multimodal Learning
We propose RAGPT, a novel retrieval-augmented dynamic prompt-tuning framework for enhancing the robustness of pre-trained Multimodal Transformer under modality missing conditions.

Biting Off More Than You Can Detect: Retrieval-Augmented Multimodal Experts for Short Video Hate Detection
Jian Lang, Rongpei Hong, Jin Xu, Xovee Xu, Yili Li, Fan Zhou† († corresponding author)
The Web Conference (WWW) 2025 CCF-A Video Analysis & Detection
We introduce MoRE (Mixture of Retrieval-augmented multimodal Experts), a novel framework designed to enhance short video hate detection.
Biting Off More Than You Can Detect: Retrieval-Augmented Multimodal Experts for Short Video Hate Detection
Jian Lang, Rongpei Hong, Jin Xu, Xovee Xu, Yili Li, Fan Zhou† († corresponding author)
The Web Conference (WWW) 2025 CCF-A Video Analysis & Detection
We introduce MoRE (Mixture of Retrieval-augmented multimodal Experts), a novel framework designed to enhance short video hate detection.
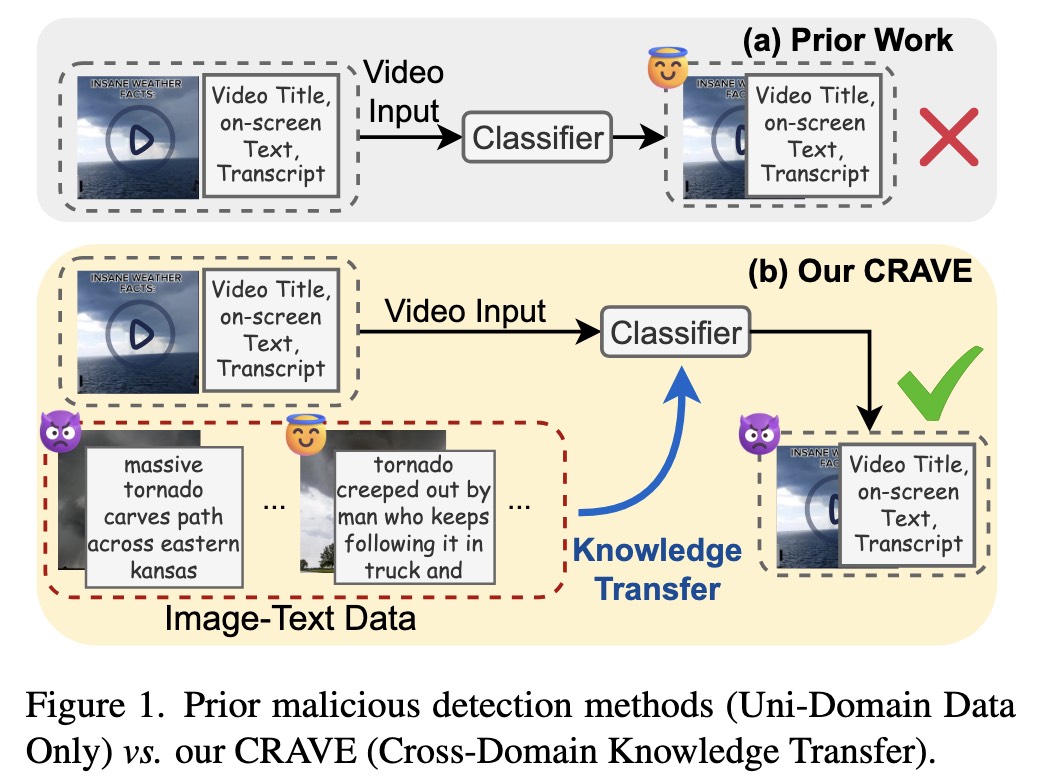
Borrowing Eyes for the Blind Spot: Overcoming Data Scarcity in Malicious Video Detection via Cross-Domain Retrieval Augmentation
Rongpei Hong*, Jian Lang*, Ting Zhong, Fan Zhou† (* equal contribution, † corresponding author)
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2025 CCF-A Video Analysis & Detection
We propose CRAVE, a novel CRoss-domAin retrieVal augmEntation framework that transfers knowledge from resource-rich image-text domain to enhance malicious video detection.
Borrowing Eyes for the Blind Spot: Overcoming Data Scarcity in Malicious Video Detection via Cross-Domain Retrieval Augmentation
Rongpei Hong*, Jian Lang*, Ting Zhong, Fan Zhou† (* equal contribution, † corresponding author)
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2025 CCF-A Video Analysis & Detection
We propose CRAVE, a novel CRoss-domAin retrieVal augmEntation framework that transfers knowledge from resource-rich image-text domain to enhance malicious video detection.
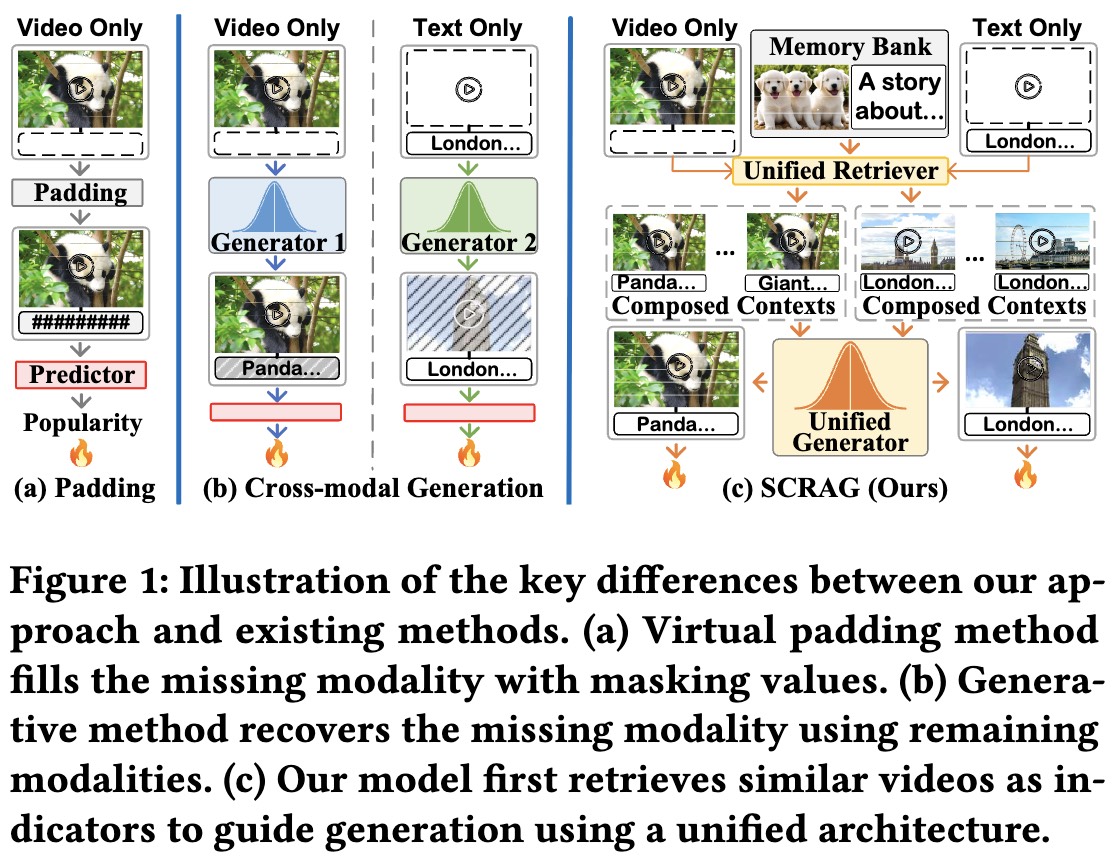
Seeing the Unseen in Micro-Video Popularity Prediction: Self-Correlation Retrieval for Missing Modality Generation
Zhangtao Cheng*, Jian Lang*, Ting Zhong, Fan Zhou† (* equal contribution, † corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2025 CCF-A Robustness Multimodal Learning Video Analysis & Detection
We propose SCRAG, a novel Self-Correlation Retrieval-Augmented Generative framework designed to enhance missing-modality robustness in micro-video popularity prediction.
Seeing the Unseen in Micro-Video Popularity Prediction: Self-Correlation Retrieval for Missing Modality Generation
Zhangtao Cheng*, Jian Lang*, Ting Zhong, Fan Zhou† (* equal contribution, † corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2025 CCF-A Robustness Multimodal Learning Video Analysis & Detection
We propose SCRAG, a novel Self-Correlation Retrieval-Augmented Generative framework designed to enhance missing-modality robustness in micro-video popularity prediction.

Following Clues, Approaching the Truth: Explainable Micro-Video Rumor Detection via Chain-of-Thought Reasoning
Rongpei Hong, Jian Lang, Jin Xu, Zhangtao Cheng, Ting Zhong†, Fan Zhou († corresponding author)
The Web Conference (WWW) 2025 CCF-A Video Analysis & Detection
In this work, we introduce ExMRD, a novel Explainable Micro-video Rumor Detection (MVRD) framework designed to generate detailed and coherent explanations for enhancing MVRD.
Following Clues, Approaching the Truth: Explainable Micro-Video Rumor Detection via Chain-of-Thought Reasoning
Rongpei Hong, Jian Lang, Jin Xu, Zhangtao Cheng, Ting Zhong†, Fan Zhou († corresponding author)
The Web Conference (WWW) 2025 CCF-A Video Analysis & Detection
In this work, we introduce ExMRD, a novel Explainable Micro-video Rumor Detection (MVRD) framework designed to generate detailed and coherent explanations for enhancing MVRD.

REAL: Retrieval-Augmented Prototype Alignment for Improved Fake News Video Detection
Yili Li, Jian Lang, Rongpei Hong, Qing Chen, Zhangtao Cheng, Jia Chen, Ting Zhong, Fan Zhou† († corresponding author)
IEEE International Conference on Multimedia & Expo (ICME) 2025 CCF-B Video Analysis & Detection
We propose a novel model-agnostic framework REAL that generates manipulation-aware representations to enhance existing methods in detecting fake news videos.
REAL: Retrieval-Augmented Prototype Alignment for Improved Fake News Video Detection
Yili Li, Jian Lang, Rongpei Hong, Qing Chen, Zhangtao Cheng, Jia Chen, Ting Zhong, Fan Zhou† († corresponding author)
IEEE International Conference on Multimedia & Expo (ICME) 2025 CCF-B Video Analysis & Detection
We propose a novel model-agnostic framework REAL that generates manipulation-aware representations to enhance existing methods in detecting fake news videos.
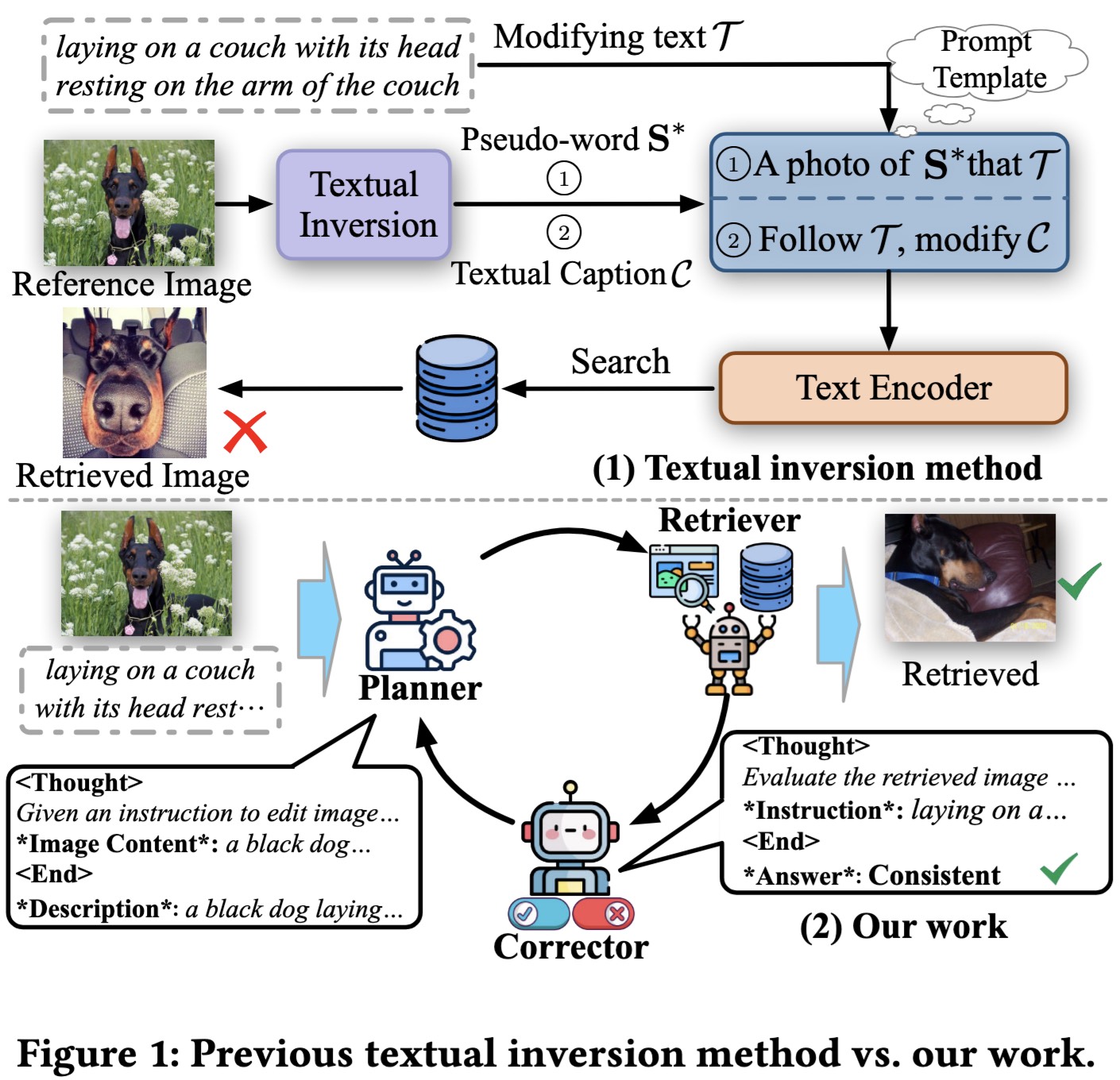
Generative Thinking, Corrective Action: User-Friendly Composed Image Retrieval via Automatic Multi-Agent Collaboration
Zhangtao Cheng, Yuhao Ma, Jian Lang, Rongpei Hong, Kunpeng Zhang, Yong Wang, Ting Zhong, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2025 CCF-A Composed Image Retrieval
We propose a novel framework -- Automatic Multi-Agent Collaboration for Zero-Shot Composed Image Retrieval (AutoCIR).
Generative Thinking, Corrective Action: User-Friendly Composed Image Retrieval via Automatic Multi-Agent Collaboration
Zhangtao Cheng, Yuhao Ma, Jian Lang, Rongpei Hong, Kunpeng Zhang, Yong Wang, Ting Zhong, Fan Zhou† († corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2025 CCF-A Composed Image Retrieval
We propose a novel framework -- Automatic Multi-Agent Collaboration for Zero-Shot Composed Image Retrieval (AutoCIR).
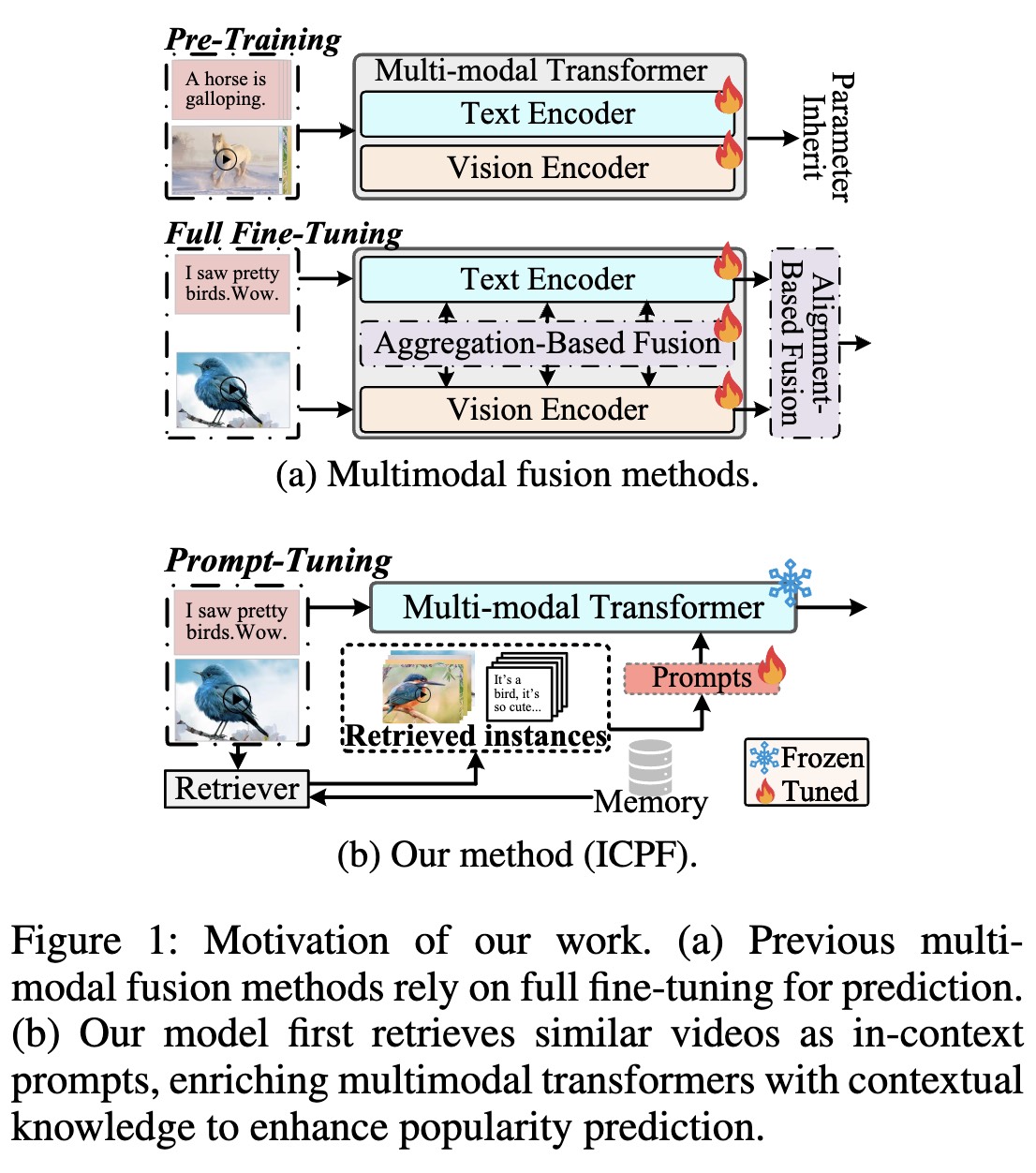
In-context Prompt-augmented Micro-video Popularity Prediction
Zhangtao Cheng, Jiao Li, Jian Lang, Ting Zhong, Fan Zhou† († corresponding author)
The Association for the Advancement of Artificial Intelligence (AAAI) 2025 CCF-A Video Analysis & Detection
Inspired by prompt learning, we propose ICPF, a novel In-Context Prompt-augmented Framework to enhance popularity prediction.
In-context Prompt-augmented Micro-video Popularity Prediction
Zhangtao Cheng, Jiao Li, Jian Lang, Ting Zhong, Fan Zhou† († corresponding author)
The Association for the Advancement of Artificial Intelligence (AAAI) 2025 CCF-A Video Analysis & Detection
Inspired by prompt learning, we propose ICPF, a novel In-Context Prompt-augmented Framework to enhance popularity prediction.
2024
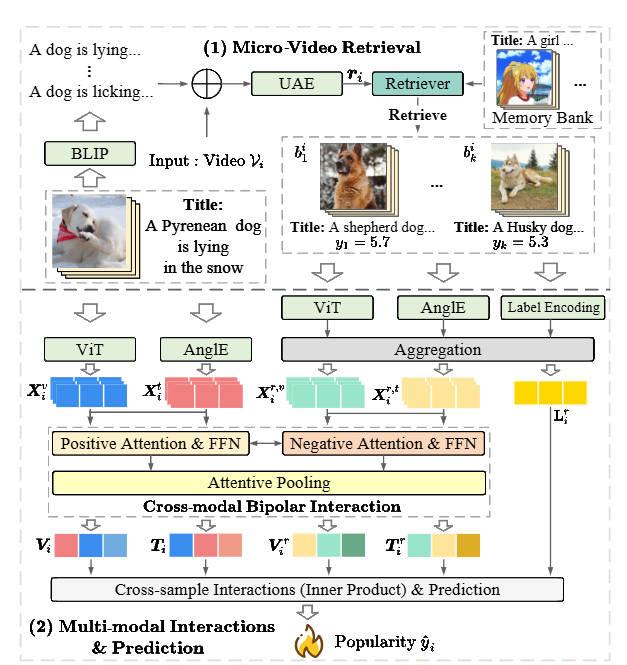
Predicting Micro-video Popularity via Multi-modal Retrieval Augmentation
Ting Zhong, Jian Lang, Yifan Zhang, Zhangtao Cheng†, Kunpeng Zhang, Fan Zhou († corresponding author)
Special Interest Group on Information Retrieval (SIGIR) 2024 CCF-A Video Analysis & Detection
We present MMRA, a multi-modal retrieval-augmented popularity prediction model that enhances prediction accuracy using relevant retrieved information.
Predicting Micro-video Popularity via Multi-modal Retrieval Augmentation
Ting Zhong, Jian Lang, Yifan Zhang, Zhangtao Cheng†, Kunpeng Zhang, Fan Zhou († corresponding author)
Special Interest Group on Information Retrieval (SIGIR) 2024 CCF-A Video Analysis & Detection
We present MMRA, a multi-modal retrieval-augmented popularity prediction model that enhances prediction accuracy using relevant retrieved information.